Forum tip: Always check when replies were posted. Technology evolves quickly, so some answers may not be up-to-date anymore.
-
 Richard G
0I am trying out MSP to do server backups, and have started an initial backup of about 400Gbytes, including many small files. I am backing up a VM from AWS east, and am using MSP with storage buckets at Backblaze. My question is how long I should expect this backup to take? The system is not heavily loaded, and very little CPU or memory is in use. But data is being processed at < 2MB/s, which implies a long, long time to complete. Subsequent backups will of course be faster.
Richard G
0I am trying out MSP to do server backups, and have started an initial backup of about 400Gbytes, including many small files. I am backing up a VM from AWS east, and am using MSP with storage buckets at Backblaze. My question is how long I should expect this backup to take? The system is not heavily loaded, and very little CPU or memory is in use. But data is being processed at < 2MB/s, which implies a long, long time to complete. Subsequent backups will of course be faster.
Is there any reason why the processing is so slow? I am using encryption and compression, BTW. Another question is whether I would be better off backing up directly into buckets at AWS East, rather than going through Backblaze.
And response would be appreciated. Thanks!
Rich
-
 David Gugick
118Performance depends entirely on bandwidth variables like: Disk read speed, CPU cores available, threads used in the backup product, network speed, data egress speed from AWS, data ingress speed at Backblaze. It's hard to say what is causing the 16 Gbit speeds you're hitting. Both services can support faster speeds than that, so it's more than likely a VM performance issue.How fast can you read data in the VM? What network speed do your virtual adapters support? How many threads are you using in CloudBerry Backup (in Options | Advanced)? What about file sizes of the files being backed up? Are they small, large?
David Gugick
118Performance depends entirely on bandwidth variables like: Disk read speed, CPU cores available, threads used in the backup product, network speed, data egress speed from AWS, data ingress speed at Backblaze. It's hard to say what is causing the 16 Gbit speeds you're hitting. Both services can support faster speeds than that, so it's more than likely a VM performance issue.How fast can you read data in the VM? What network speed do your virtual adapters support? How many threads are you using in CloudBerry Backup (in Options | Advanced)? What about file sizes of the files being backed up? Are they small, large? -
Richard G
0David, thanks for your response. The backup is now running slower, at 471.54KB/s, according to the web monitor application. Many of the files are, indeed small, some very small like log files and the like, but the progress should still be better.
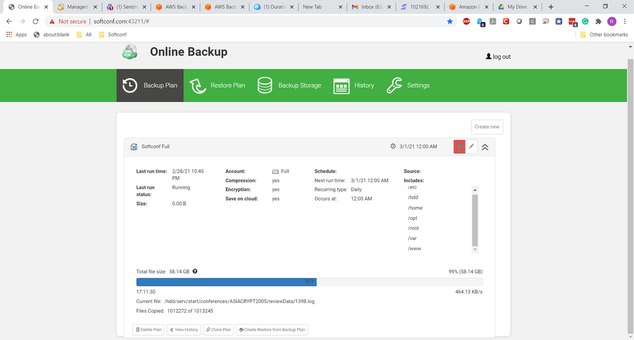
https://drive.google.com/file/d/1c_9BELUwEoxDTQnQPvwe9wvVnWLh3Z_Z/view?usp=sharing
This Amazon instance is m5ad.2xlarge, with 8 vCPUs (AMD EPYC 7000), 32Gbyte memory and NVMe SSD storage. Here is the view from htop:
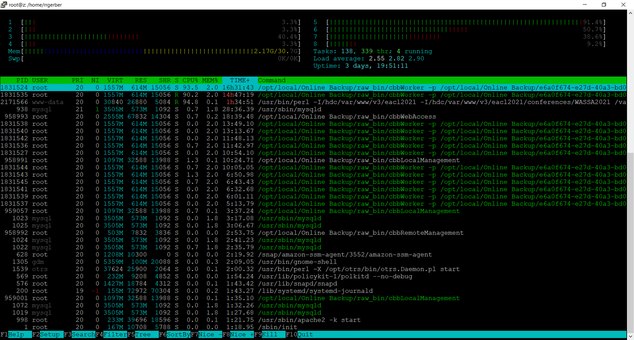
https://drive.google.com/file/d/17xiBetX3GnNHupjOk6vGPIU2lORusMTW/view?usp=sharing
As you can see, the backup software is basically the only significant running process.
Can you suggest anything that would help?
Thanks,
Rich -
Richard G
0I should add that the file system contains over 5,000,000 files, many of them in pdf and txt format. I see that under the cloudberry directory /CBB_z.softconf.com, so far hundreds of thousands of subdirectories have been created, each one corresponding to one of the 5,000,000 files. So I assume that all of the files have to be individually encrypted and compressed, and then a directory is created for each.
Is this the cause of the slowness, and is there anything that can be done to speed up the process? I need the ability for single file restoration, so backing up an image of the filesystem isn't the solution for me. (We already have snapshots done with AWS)
Best,
Rich -
David Gugick
118The issue isn't directories and files as such. With object storage they are in fact the same thing anyway. But what you are going to see is latency issues as each file that needs to be created, whether that's a object folder or the object file itself is going to have latency as a result of the round trip out of AWS to Backblaze. One way to reduce the effects of the latency is to increase the thread count. You didn't reply what you have it said to in the backup product, so please reply with that number. Also keep in mind that this is a one-time trip, and even if it takes a few days that may not be a problem for you. But in the interim let's find out what your threads are set to. You can also set the logging to off if it's turned on. But even with it turned off I don't suspect that's going to make much of a difference with NVMe drives.
-
Richard G
0I really appreciate the quick response. I just started with MSP yesterday, and was not aware that I could set the thread count. I suppose I am using the default configuration, which is:
config/.default_settings.conf:MinThreadCount : 10
config/.default_settings.conf:MultiThread threads count : 5
config/.default_settings.conf:MultiThread memory usage : 104857600
Would you suggest changing those numbers? And FYI, I am comfortable with the initial backup taking a few days, as long as the subsequent daily backups are faster. If I recall from the Solar Winds MXP product I used, only about 6GBytes were processed daily, most of which consisted of binary database files, which cannot be compressed.
I like the product and will definitely buy the "ultimate" subscription, as long as file restore works the way I expect it to.
Best,
Rich -
Richard G
0BTW, I couldn't find much documentation on installing the product from bash in Linux, until I came across the excellent instructions provided by the Average Linux User here: Cloudberry Backup for Linux Server . You should probably link to this somewhere on product pages, since it is very useful to Linux people, and I found it invaluable.
-
David Gugick
118Change the settings from the UI if you can (https://help.msp360.com/cloudberry-backup-mac-linux/settings/advance-settings) - should be similar in the web client.
You can try changing the threads as they appear in Settings - Advanced higher and see if that helps. I can't tell from what you posted from the config file if it's set at 5 or 10, but try setting to 20 and see if it helps throughput. -
Richard G
0OK, thanks for the info. I am working in a server environment with CLI only, so I will try to find the relevant setting - but not until the initial reference backup is finished. I don't want to mess with anything while it's in progress.
Thanks, RIch -
Richard GAccepted Answer
0David, I have another question. The initial reference backup is still running, which may be expected with the first backup of 7,000,000 files. But when it started a few days ago, the 1Terabyte partition was about 50% used, of which 45% of that was in the backup plan.
The backup is using the same partition for its temporary storage before uploading to the cloud. The problem is that it's now up to 79% used, and the backup is not nearly over. I am afraid I will run out of space before it is finished.
In mid-backup, is there any way to force Cloudberry to start uploading to the cloud, and release that temporary storage? Or more generally, is there a way to set the maximum temporary storage amount in the CLI on linux. (I saw something to that effect for Windows, but I am working in a server environment.)
Thanks!
Rich -
David Gugick
118I am unaware we use that type of temporary space when uploading directly to the cloud, which I believe you are doing. I do not know what files you are seeing int he temp folder. How much space are we talking about? Do you happen to have logging enabled to High?
BTW, I am checking with Support. -
Richard G
0I checked with support, and after viewing the logs, they said that I had not correlated the server's backup agent with the backup storage selected with my storage account. And hence my error. The only option provided in the server's backup manager is the "File System". No cloud source is available. And yet this is what is in my account:
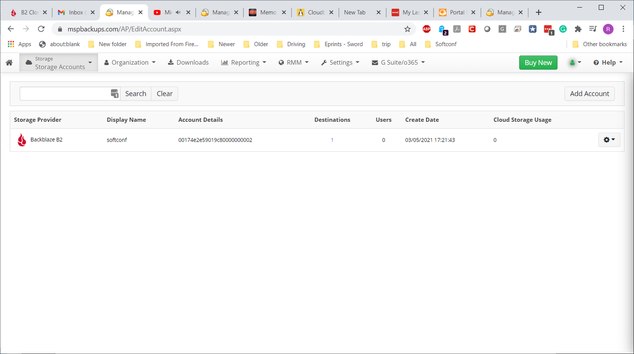
This backup location is unknown to the Cloudberry agent on my server. So what am I doing wrong?
Rich -
David Gugick
118once you define the storage account, you need to create a backup destination on that same screen, which is really just a bucket name and a region if the cloud storage provider has multiple regions. Then you need to go into the customer in question that you're working on, and add that storage account at the customer or company level as we call it in the product. Then you create a backup plan and for the storage options for that plan you assign it the storage destination that you just created. If on the other hand you want to use a hybrid backup that backs up to the local network and the cloud at the same time then you would have to make sure you've created the file system storage account for the network location where you want the backup saved, and then you would also assign that account to the customer, and finally you would select hybrid as the backup type in the backup plan and make sure that both the local network storage account and the cloud destination are selected as targets.
-
Richard G
0Thanks, David.
I have been trying, without success, to launch a backup plan. I will go through the steps I used to get there. I can't figure out what is going wrong.
Adding a storage account: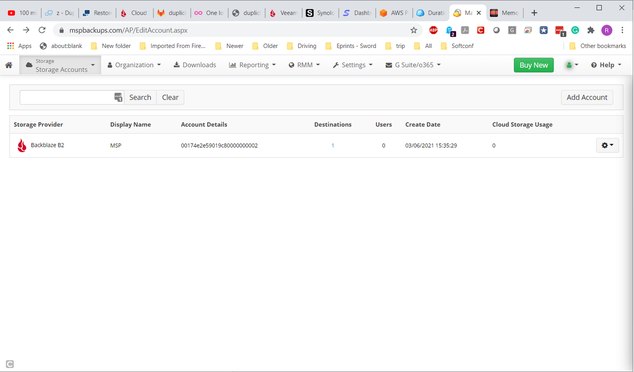
Need to add user: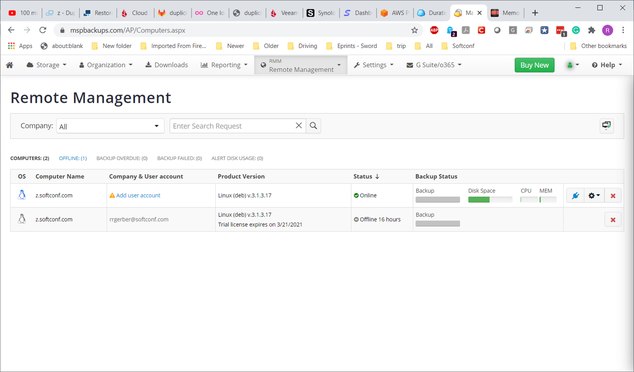
User added: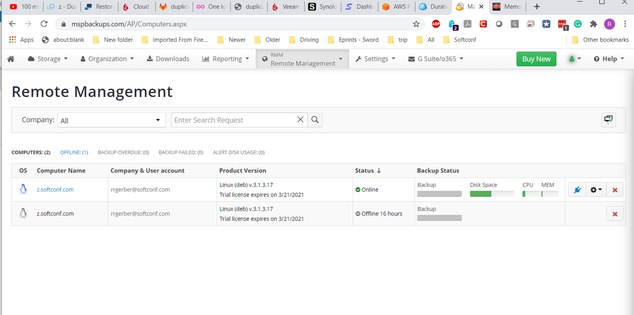
Now, from remote management, try to add backup plan: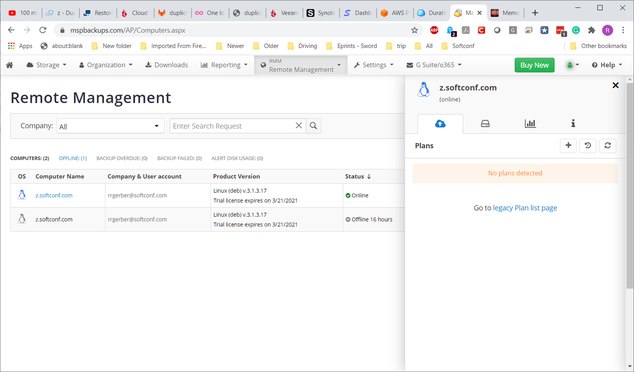
Creating backup plan, but destinations are not selectable.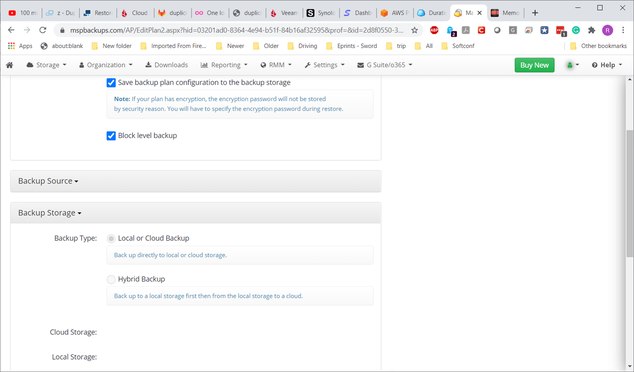
Anyway, try to run the backup, which results in failure: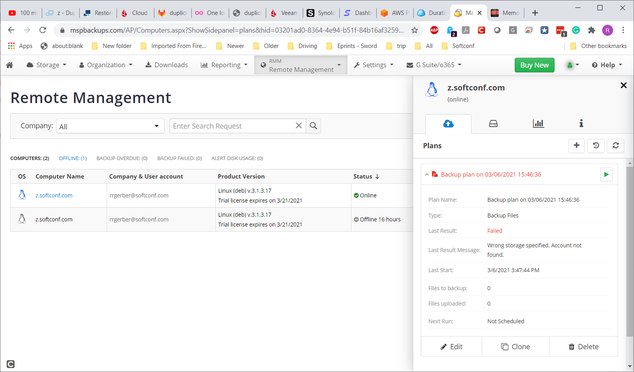
I realize I am doing something wrong, but I can't determine what it is. I need to go through a simple test backup and restore before I can put this product into production on my various servers. I am usually pretty good at setting up software, but this seems to be particularly challenging. -
David Gugick
118You don't need to assign the storage to the user. You can do it that way and that's the way it was traditionally was done, but as I stated above you can assign the storage to the customer directly if that is more convenient for you to do. But it sounds like you figured it out.
-
Richard G
0Thanks David. Even on a Sunday! I have one last question. From my experimentation yesterday, I learned the hard way that since I am on AWS, backing to Backblaze will be very expensive. So I tried to add S3 as a provider, but the storage account manager will only allow adding buckets at Backblaze (and local filesystem storage). Is there a way to add other providers? Thanks.
-
David Gugick
118When you add a storage account in the managed backup UI, you would need to select Amazon S3 as the storage account. Then you can click the gear icon and add a backup destination bucket in the same region where the data already resides. Then you would add that storage account to the customer (or user as you had done previously) and create a new backup plan that uses the new storage account (or edit the existing one and simply change the storage destination).
-
Richard G
0Thanks, David. The problem was when I set up my account, I landed on your page via a link from Backblaze. According to support, that is an affiliate agreement - if you are referred from Backblaze you only have the option of using B2. It caused a lot of confusion, which I solved by installing a stand-alone version with a different username. So I'm good now, at least for testing. Thanks for all your help. Rich.
-
David Gugick
118I am unaware of such a limitation with managed backup. Stand-alone is not managed and requires a perpetual license after trial. Are you a managed service provider? If not, and you only need a single license, then stand-alone would likely be a better option.
-
Richard G
0Thanks. We are a service provider, but the service has nothing to do with reselling internet services from other companies to consumers. We just need server backups for single Linux machines. If a client needs something from backup, we restore it for him. So the stand-alone license (or several of them) is fine. For what it's worth, the sales person told me that, in fact, if you get referred from Backblaze then you are limited to B2.
Anyway, I am currently backing up to S3, and it's going at the rate of 500KB/sec. So it will take another few days, but that is OK for the first reference backup. My main concern the duration of time required to restore. I suppose the slow backup is partially due to building index structures in the database, so that it's easy to find files to restore. I have tried to use Duplicity for this, but it takes forever to load the directory structure, and then 5 minutes just to open /var. Even in the CLI it requires the same amount of time. I have previously used the SolarWinds backup system for this, and it is really fast. But it would be outrageously expensive to pay the egress fees at AWS for that. Hence my interest in Cloudberry.
Rich -
Richard G
0
After 5 days of running, the first backup completed. I tried restoring a few files from the backup, which worked fine. The last step in my evaluation was to re-run the backup plan, to determine how long the incremental backup would take.
However, after "thinking" for about 30 seconds, it came back with a "failed" status, and re-sent the email from the first backup, done 1 hour previously, which reads "Your backup plan Backup completed with warnings, please see below for more details. The report indicates that some files could not be backed up, because they had root permission only. And for this reason, the status was set to "FAIL" on the entire backup, which is preventing another backup with the same plan. Is there any way to resolve this problem? After five days of waiting, it is rather disappointing that the backup cannot be used as a reference for future backups, solely because some files were unreadable. -
David Gugick
118The incremental should be good, with the exception that some files were not backed up. It doesn't mean that the entire backup failed. if those files in question do not need to be backed up, and they were explicitly selected in the backup, you can uncheck them, you can back them up with a different plan. Or I can we can find out if you can run the process under a different user that has broader permissions to access the files in question. What I would do now is go through a test restore process for one of the files that had an incremental backup just to satisfy yourself that the latest backup, despite the failures of some files, can still restore all the other files that were backed up.
-
Richard G
0Hi David, thanks for your response. I'll try to be thorough in describing the problem. First, a question: After a backup finishes, can I run it again manually to get an incremental backup, or do I have to wait for the next scheduled time?
1. Here is what happens when I run it manually (by clicking on the arrow): It sends me an email with the results of the previous backup, rather than starting a new one. Here is what is in the log:
2021-03-13 15:37:29,499729 [INFO ]: [ CBB ] [ 8 ] Request force run plan "{4f07fc9e-556c-48cc-a917-53ea8574bb70}". Request from id: {17b25f01-805a-402b-970c-e59ef447949f} 2021-03-13 15:37:29,500091 [INFO ]: [ CBB ] [ 8 ] Run plan: QUuid({4f07fc9e-556c-48cc-a917-53ea8574bb70}) Softconf Backup 2021-03-13 15:37:29,501025 [INFO ]: [ CBB ] [ 8 ] Plan started: QUuid({4f07fc9e-556c-48cc-a917-53ea8574bb70}) Softconf Backup 2021-03-13 15:37:29,523658 [ERROR]: [ CBB ] [ 8 ] QUuid({4f07fc9e-556c-48cc-a917-53ea8574bb70}) :part: 0.cbl.log: [ CBB ] [ 1 ] Rebranding: QMap((AllowCompression, QVariant(bool, true))(AllowConsole, QVariant(bool, true))(AllowEncryption, QVariant(bool, true))(AllowFileSystemAccount, QVariant(bool, true))(AllowRemoteConnection, QVariant(bool, false))(CompanyName, QVariant(QString, CloudBerry Lab))(ContactEmail, QVariant(QString, supportatcloudberrylabdotcom))(CopyrightText, QVariant(QString, Copyright 2021 CloudBerry Lab Inc.))(DefaultUseCompression, QVariant(bool, false))(DenyBackupPlanEdit, QVariant(bool, false))(DenyRestoreWizardOpening, QVariant(bool, false))(DenyStorageMenuItemDelete, QVariant(bool, false))(ProductName, QVariant(QString, CloudBerry Backup))(S3Accelerate, QVariant(bool, true))(S3StorageClass, QVariant(QString, STANDARD))(SSE, QVariant(bool, false))(SignUpEnabled, QVariant(bool, false))(WebSite, QVariant(QString, http://www.cloudberrylab.com/))(showS3Accelerate, QVariant(bool, false))(showSIA, QVariant(bool, true))(showSSE, QVariant(bool, true))) 2021-03-13 15:37:33,518977 [INFO ]: [ CBB ] [ 8 ] QUuid({4f07fc9e-556c-48cc-a917-53ea8574bb70}) Softconf Backup : Listing Process: 2021-03-13 15:37:33,519013 [INFO ]: [ CBB ] [ 8 ] 2021-03-13 15:37:33,519027 [INFO ]: [ CBB ] [ 8 ] End Listing : Status: QProcess::ExitStatus(NormalExit) code 0
That is all that happens, aside from getting another report from the first backup.
2. When I run a restore plan, I get similar behavior: The console pauses for a moment and returns with the status "Never Run". Meanwhile the log has this:
2021-03-13 15:33:12,678559 [INFO ]: [ CBB ] [ 8 ] Request force run plan "{7868628f-4d9d-416b-afef-a6cf883a7e28}". Request from id: {f164ae0f-3f40-4642-9f32-9a43d81c528d} 2021-03-13 15:33:12,678938 [INFO ]: [ CBB ] [ 8 ] Run plan: QUuid({7868628f-4d9d-416b-afef-a6cf883a7e28}) Restore plan on 3/13/21 3:28 PM 2021-03-13 15:33:12,679629 [INFO ]: [ CBB ] [ 8 ] Plan started: QUuid({7868628f-4d9d-416b-afef-a6cf883a7e28}) Restore plan on 3/13/21 3:28 PM 2021-03-13 15:33:12,701246 [ERROR]: [ CBB ] [ 8 ] QUuid({7868628f-4d9d-416b-afef-a6cf883a7e28}) :part: 0.cbl.log: [ CBB ] [ 1 ] Rebranding: QMap((AllowCompression, QVariant(bool, true))(AllowConsole, QVariant(bool, true))(AllowEncryption, QVariant(bool, true))(AllowFileSystemAccount, QVariant(bool, true))(AllowRemoteConnection, QVariant(bool, false))(CompanyName, QVariant(QString, CloudBerry Lab))(ContactEmail, QVariant(QString, supportatcloudberrylabdotcom))(CopyrightText, QVariant(QString, Copyright 2021 CloudBerry Lab Inc.))(DefaultUseCompression, QVariant(bool, false))(DenyBackupPlanEdit, QVariant(bool, false))(DenyRestoreWizardOpening, QVariant(bool, false))(DenyStorageMenuItemDelete, QVariant(bool, false))(ProductName, QVariant(QString, CloudBerry Backup))(S3Accelerate, QVariant(bool, true))(S3StorageClass, QVariant(QString, STANDARD))(SSE, QVariant(bool, false))(SignUpEnabled, QVariant(bool, false))(WebSite, QVariant(QString, http://www.cloudberrylab.com/))(showS3Accelerate, QVariant(bool, false))(showSIA, QVariant(bool, true))(showSSE, QVariant(bool, true))) 2021-03-13 15:33:16,919322 [INFO ]: [ CBB ] [ 8 ] QUuid({7868628f-4d9d-416b-afef-a6cf883a7e28}) Restore plan on 3/13/21 3:28 PM : Listing Process: 2021-03-13 15:33:16,919358 [INFO ]: [ CBB ] [ 8 ] 2021-03-13 15:33:16,919371 [INFO ]: [ CBB ] [ 8 ] End Listing : Status: QProcess::ExitStatus(NormalExit) code 0 2021-03-13 15:33:16,920248 [ERROR]: [ CBB ] [ 8 ] PlanFinishedReport: planId: {7868628f-4d9d-416b-afef-a6cf883a7e28} << planName: Restore plan on 3/13/21 3:28 PM error
I checked the storage bucket on S3, and there are objects corresponding to all the data I am trying to restore. Can you tell me what I did wrong?
Regards,
Rich -
 Sergey Kosintsev
0Hello Rich,
Sergey Kosintsev
0Hello Rich,
0. The backup can be started manually right after the previous backup job has run.
Please send us the logs from the machine so we can answer your further questions.
Please go to the Remote Management tab in your MBS Online Console (http://mspbackups.com/Admin/Computers.aspx), choose the machine in question and under Gear button there will be an option to send us the logs remotely, you can specify ticket 61808.
Best Regards,












Welcome to MSP360 Forum!
Thank you for visiting! Please take a moment to register so that you can participate in discussions!
Categories
- MSP360 Managed Products
- Managed Backup - General
- Managed Backup Windows
- Managed Backup Mac
- Managed Backup Linux
- Managed Backup SQL Server
- Managed Backup Exchange
- Managed Backup Microsoft 365
- Managed Backup G Workspace
- RMM
- Connect (Managed)
- Deep Instinct
- CloudBerry Backup
- Backup Windows
- Backup Mac
- Backup for Linux
- Backup SQL Server
- Backup Exchange
- Connect Free/Pro (Remote Desktop)
- CloudBerry Explorer
- CloudBerry Drive
More Discussions
- Terms of Service
- Useful Hints and Tips
- Sign In
- © 2025 MSP360 Forum