Forum tip: Always check when replies were posted. Technology evolves quickly, so some answers may not be up-to-date anymore.
Comments
-
Move computer to another User AccountI am checking with the team to understand all implication to existing backups when changing a user account. I will reply when I hear backup. Thanks.
-
constraint failed UNIQUE constraint failed: cloud_files.destination_id, cloud_files.local_pathThis is a SQL Server database backup plan? Can you verify the agent version?
-
VM File Level Restore - How to select multiple files?according to the team:
Multiple selection for item-level restore is available in new backup format for both Hyper-V and VMware.
With legacy format, you still can select multiple folders or files, but only on a single level from the right pane.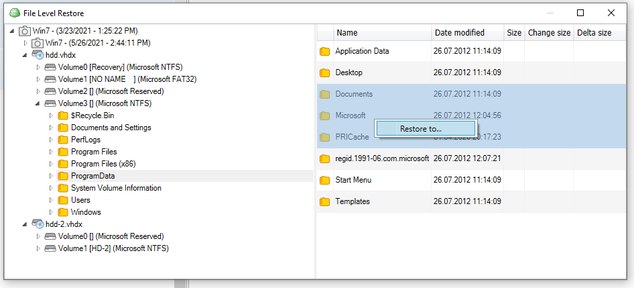
-
Manually Purging Hyper-V BackupsMy guess is you have the ability to delete backups in the agent disabled. That setting is disabled by default and should remain so after you change it in order to facilitate the delete. It's a safety measure to ensure someone accessing the agent cannot delete backups.
Go to the management console - Settings - Global Agent Options and check “Enable ability to delete files from the Storage tab”. After the change, you may have to close and restart the agent. Afterwards you should disable the option to protect the backups. -
Manually Purging Hyper-V BackupsI do not have a local Hyper-V install, so I am checking with the team. I'll reply back tomorrow with an answer.
-
Device not readythis may be a known issue with some customers. I would strongly encourage you to open a support case and send the logs using the tools diagnostic toolbar option on one of the agents that is experiencing the issue. Or, you can send the logs from the Management Console from Remote Management - and click the gear icon and select Send Logs.
Support will be able to recommend a workaround and communicate with you when it will be fixed. -
VM File Level Restore - How to select multiple files?have you tried just clicking the check boxes next to the file or folder names rather than the file and folder names, themselves? Are you saying your check boxes are not on the left? Maybe a screenshot would help. I'm hoping this is just a matter of where you are clicking, but we'll get to the bottom of it.
-
VM File Level Restore - How to select multiple files?Can you provide details about the restore process and why you are unable to restore more than one file or folder at a time? What happens when you try to select more than one file and / or folder?
-
Manually Purging Hyper-V BackupsCan you describe in a little bit more detail what you're trying to do? If it's just a matter of deleting an old backup set, you can do that from the storage tab in the agent. But I'm guessing what you're trying to do is maybe a little different. Thanks.
-
Immutable BackupsIt's coming in September. Thanks for asking. We'll post here when it's available.
-
Glacier and new Backup format in-cloud copyI do not believe synthetic fulls work in S3 Glacier. Glacier is designed for archival storage and I do not think it has the necessary APIs to perform the synthetic full. When it comes time to restore from Glacier, you can do standard or expedited delivery depending on your SLAs for getting access to the data. Expedited is more expensive. There is a new storage class called glacier instant retrieval that we support and I believe that storage class will allow you to access the data immediately.
I do not generally recommend backing up directly to S3 glacier. You can do it, but in my experience glacier is best used for archival storage. In other words, long-term storage on data that you don't plan to change and that you don't plan to restore from unless absolutely necessary. In other words, for compliance and emergencies. You could back up to a storage class like S3 standard or S3 and infrequent access, and use a lifecycle policy to automatically move that data after some time has passed, for example 30 or 60 days, to glacier for long-term storage. If you do that and you're outside your full backup schedule, then you're effectively moving data that will never change.
Glacier does have minimum retention periods. If I'm not mistaken, regular glacier is 90 days, and glacier deep archive is 180 days. You can use standard or expedited retrieval. And then there's the new storage class called glacier instant retrieval. It can get a little confusing and pricing varies between the different storage classes and restore options; not only in what you pay for the storage, but how much it will cost you to restore the data - egress from glacier.
So I would strongly encourage you to use the AWS calculator for glacier and type in some examples of how much data you might be restoring and doing that for the different storage classes and restore types, so you can understand better what you are going to pay in order to restore that data. and so you can have these prices negotiated properly, in advance, with your customers so there are no surprises.
https://calculator.aws/#/
https://aws.amazon.com/s3/storage-classes
https://aws.amazon.com/s3/storage-classes-infographic/
https://aws.amazon.com/s3/storage-classes/glacier/ -
New Backup Format: Run Full Every 6 months, is it safe?That's correct if you're keeping 3 months with a 3 Month Full Backup schedule.
-
New Backup Format: Run Full Every 6 months, is it safe?Sounds like a good plan.
I think you could probably decide on a few default options for customers and then have the conversations with them about anything they need over and above. For example you could use the new backup format for cloud backups with 6 months of deleted file restorability, and then open the conversation with the customers about whether or not they need longer retention or longer deleted file restorability, and move on from there. If many customers select the default, then you don't have to worry about a custom designed backup plan for each; but you always have that option.
Feel free to post back to the forum on your progress and how things are working out for you. Also let us know if you have any further questions I can help you with. -
Region in Web URLYou need to hit the Support section of the msp360.com web site. Usually you need maintenance on a product to open a support case, but if they ask (and you do not have maintenance), then ask politely and let them know you tried the forum. If that fails, I can try to open an internal case.
Having said that, I think the product is working correctly now given the Amazon specs for URL access. I realize that the older version may not have been AWS compliant in that regard. Why can't you use the recommended URL style, if I may ask? Is it because you have an application expecting the old format and changes would be difficult?
What happens when you upload a file to your S3 bucket using the AWS Management Console - is the URL format the same as Explorer or does it use the older format? Just curious.
And I guess I should have asked: Is this the paid or free version of Explorer. If the free version, you will not be able to open a support case... -
Region in Web URLAlso see if this helps:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/VirtualHosting.html#VirtualHostingCustomURLs
Otherwise, you can open a support case as I am not sure if the issue you're running into is something that was supported by Amazon but has been deprecated, or it's something that can be changed it the product or your application that accesses the objects. -
Region in Web URLAs far as I can tell from AWS docs, the region is a part of the full name you use to access objects in Amazon S3: https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-bucket-intro.html
I am not sure about the format you are using. From what I can see, there are two ways to access:
Virtual-hosted–style access:Path-style access:https://bucket-name.s3.region-code.amazonaws.com/key-name
https://s3.region-code.amazonaws.com/bucket-name/key-name
You could try using the recommended virtual hosted style without the region and see if it works. -
Immutable Backupshow are you currently restoring from S3? Do you copy the files from S3 down to local disk and then perform a restore, or do you have some way to restore directly from S3?
Using the new backup format we store things in archive files, so there won't be a list of files that match what you have locally in the cloud. The way you have things set up, you may want to have different backup plans for each database, but I think you could include the t-log backups if you wanted since most backups are removed every week.
As a side-note, if you're deleting your backups locally after the next successful full backup, then you're only leaving yourself with one days' worth of backups since you're deleting the previous week. But if that process is working for you, that's fine. I would be a little concerned about that, especially since you're backing up locally and presumably you have disk space. Restoring from the cloud is certainly going to take a lot longer, and if you find yourselves restoring a few times a week, I'd be looking to keep more backups locally to avoid the need to restore from the cloud. But more backups kept locally means larger full backups on our side, so there's a trade-off.
You can run the fulls as frequently or as infrequently as you want. I assume you don't need all backups for the last 10 years, is that correct? Or are you keeping every single full and every single differential for every single database for 10 years? I guess I would need to know that to provide some guidance on retention settings.
If you're truly keeping 10 years worth of everything, then you don't need to run the fulls very frequently at all. And you may want to run them after the cleanup happens locally to minimize the next full backup size on the S3. You could run them once a month if you wanted. Or you could run them weekly if they're aligned with the local full backup and cleanup. In that case you just going to have a new full backup for the database and the rest of the folder it sounds like it's going to be cleared out anyway. So the synthetic won't really do anything as the only thing being backed up is the new full backup because that's the only file in the folder. And in that sense, a full is no different in what data is backed up than an incremental.
Use the Keep Backups For as an absolute measure of how long you need to keep the backups. Use the GFS settings if you do not need to keep every backup and are looking for longer-term retention, but less granular in restore points - or use GFS if you need immutability. -
Restore a file-level backup to Hyper-vwe only back up the used blocks. Who told you that the image will match the actual volume size?
-
Immutable Backupsa full, in your case, would be all of the files that are selected for backup. If you have some retention that's removing old backups from that folder then they obviously would not be a part of that. And if you had different backups for different databases, as an example, then each full backup would be for an individual database. An incremental backup in your case would just be any new files that are created as it's unlikely that any sql server backups that are already created are going to be modified in some way. Unless you're appending transaction log or other backup files to one another, which I generally do not recommend. then, as you create new transaction logs or differential or full backups of the databases they would be considered as a part of the incremental backup. At the end of say a month if you're using a 30-day cycle a new full would be created based on the data that's currently on your backup folder locally, while using the bits that are already in the cloud to help create that next full.
How much data you decide to keep in the cloud is going to be up to you, and likely based on your retention needs.
I don't know how you're managing the deletion of old backups if you're not using our agent to do the SQL Server backups. But let's just assume that you're intelligently removing old backup files that are no longer needed, and treating every backup set for SQL Server as a full plus any differentials plus transaction log backups - that way you're not removing a differential or a full while leaving transaction log backups in the backup folder. If that's the case then you would end up with backups in the cloud that contain all the files that are needed for a restore. Of course, if you're doing it that way you'd have to restore the files locally and then restore them to SQL Server using native SQL Server restore functionality. You couldn't restore directly to SQL Server from the cloud because you're not using our SQL Server agent.
If your retention needs are different based on the databases that are being backed up, then you would probably be best served by creating separate backup plans for each database (assuming you're backing them up to different folders) that match your retention needs in the cloud. That would keep each full backup smaller because each backup would only be dealing with a single database.
The number of fulls that you actually keep in the cloud is going to depend on your full backup schedule, your setting for Keep Backups For, and if you're using GFS what type of backups you're keeping (weekly, monthly, yearly) and how many of each.
Feel free to reply back with more details on retention needs and maybe we could dial in the right settings for your particular use case..

David Gugick

Start FollowingSend a Message
- Terms of Service
- Useful Hints and Tips
- Sign In
- © 2025 MSP360 Forum